阈值和可用性
阈值是对被监控指标预设的值,超出该值时将触发告警,有助于及时处理性能问题。平台的可用性监控通过对资源可访问性进行持续检查来确保运行状态(正常运行、宕机、告警、严重),并通过您首选的通信方式发送告警通知任何变化。
添加阈值和可用性
要添加新的阈值和可用性配置文件:
- 登录 Site24x7。
- 点击 管理 > 配置文件 > 阈值和可用性。
- 在阈值和可用性屏幕中点击添加阈值和可用性。
- 指定以下详情以添加服务的阈值和宕机规则:
- 选择监视器类型:从下拉列表中选择所需的监视器类型。
- 显示名称:提供用于识别的标签。
- 将监视器报告为宕机的位置数:从下拉列表中选择,以便在 Web 服务从指定数量的位置宕机时收到告警通知。
- 阈值配置
阈值配置将根据您为以下部分提供的值进行设置。根据您选择的监视器类型,将提供这些配置选项的组合。- 条件:从 <、>、=、<= 或 >= 中选择,设置基于与输入值操作的触发告警标准。
- 阈值:这是您可以为任意性能指标提供的值,例如 CPU 使用率百分比、内存使用量或网络延迟。这些值将与您定义的条件进行比较,以确定是否应触发告警。
- 轮询策略:轮询策略定义 Site24x7 发送请求以收集指标的时间间隔。它因资源类型和监控粒度需求而异。例如,您可能选择更频繁地轮询关键资源,而对不那么关键的资源设置更长的轮询间隔。
- 轮询值:轮询值表示在轮询间隔内从被监控资源收集的最新数据点,即正在被监控的实际测量值。此值用于与您设置的条件进行评估。
- 通知为:定义应发送告警的状态。它允许您自定义希望在资源状态变化时收到通知的时机。例如,根据您提供的值,您可以选择在值超出阈值时立即根据严重程度收到通知。
5.1 基于 Zia 的阈值:
基于 AI 的阈值将使用异常检测跟踪异常峰值,并提供动态阈值,该阈值将相应更新。如果您选择基于 AI 的阈值,请选择关联的异常严重性和相应状态。
-
高级阈值
高级阈值允许用户跨不同属性组合多个条件,确保仅在出现有意义的模式或异常时才触发告警。您可以使用逻辑运算符 &&(AND)和 ||(OR),基于单个资源的多个依赖属性(例如服务器的 CPU 和进程指标)发送自定义告警。
使用逻辑运算符可以设置组合多个实时属性的条件。例如,考虑由表达式 A &&(( B && C )|| D) 定义的条件,设置为触发严重告警。在这里,您可以配置:-
A 为 CPU 利用率,将其阈值设置为 > 80%
-
B 为内存利用率,将其阈值设置为 >75%
-
C 为 磁盘 I/O 等待时间,将其阈值设置为 60 ms
-
D 为活动进程数,将其阈值设置为 > 200
在高级阈值配置部分,您可以在单个条件中跨不同阈值条件多次使用同一属性,以实现精确的告警逻辑。例如,您可以组合多个响应时间边界,或将 CPU 和内存阈值配对以反映实际的运营场景。
当同一属性在阈值条件中被引用时,会实时验证条件以确保逻辑保持有意义。
如果条件相互矛盾且无法同时满足,则无法保存配置。例如,配置 response_time_threshold > 90 和 response_time_threshold < 90 会产生逻辑冲突,因为没有任何值能同时满足这两个条件。
系统会识别冗余条件并发出警告,但不会阻止配置。例如,配置 CPU > 90 和 CPU > 80 会使一个条件变得多余,因为更严格的条件已经涵盖了更宽泛的条件。
在设置高级阈值时,可以配置轮询策略、轮询值、通知为和自动化。
注意-
您可以配置条件来触发三种状态之一:告警、严重或宕机。
-
对于每种状态,只能配置一个条件。要为不同状态添加多个条件,请点击右侧的 + 图标。
-
高级阈值仅适用于监视器级别属性,不适用于子属性。
使用场景
-
负责管理数据中心的 DevOps 团队需要识别资源争用的早期迹象,以防止不必要的扩展。使用高级阈值,他们配置了一个告警,在 CPU 利用率超过 80% 且内存利用率超过 85%,或交换利用率超过 70% 时触发。这有助于在系统保持运行的同时检测早期资源争用。
条件:((a > 80 && b > 85) || c > 70%) -
当 Web 应用由于资源消耗高而出现性能下降时,IT 运维团队设置了一个严重告警,在 CPU 利用率超过 85% 且内存利用率超过 90%,或磁盘空间低于 10% 且网络利用率超过 90% 时触发。这会标记需要立即关注的性能问题。
条件:(a > 85% && b > 90%) || (c < 10% && d> 90%) -
当数据库服务器接近完全系统故障时,会激活宕机告警。为防止因孤立的峰值产生误报,系统管理员配置了仅在系统处于完全过载状态时才触发的宕机告警。只有当 CPU 利用率 > 90%、内存利用率 > 95% 和交换利用率 > 90% 同时发生时才触发,确保系统真正处于风险中才发出告警。
条件:(a > 90 && b > 95 && c > 90%)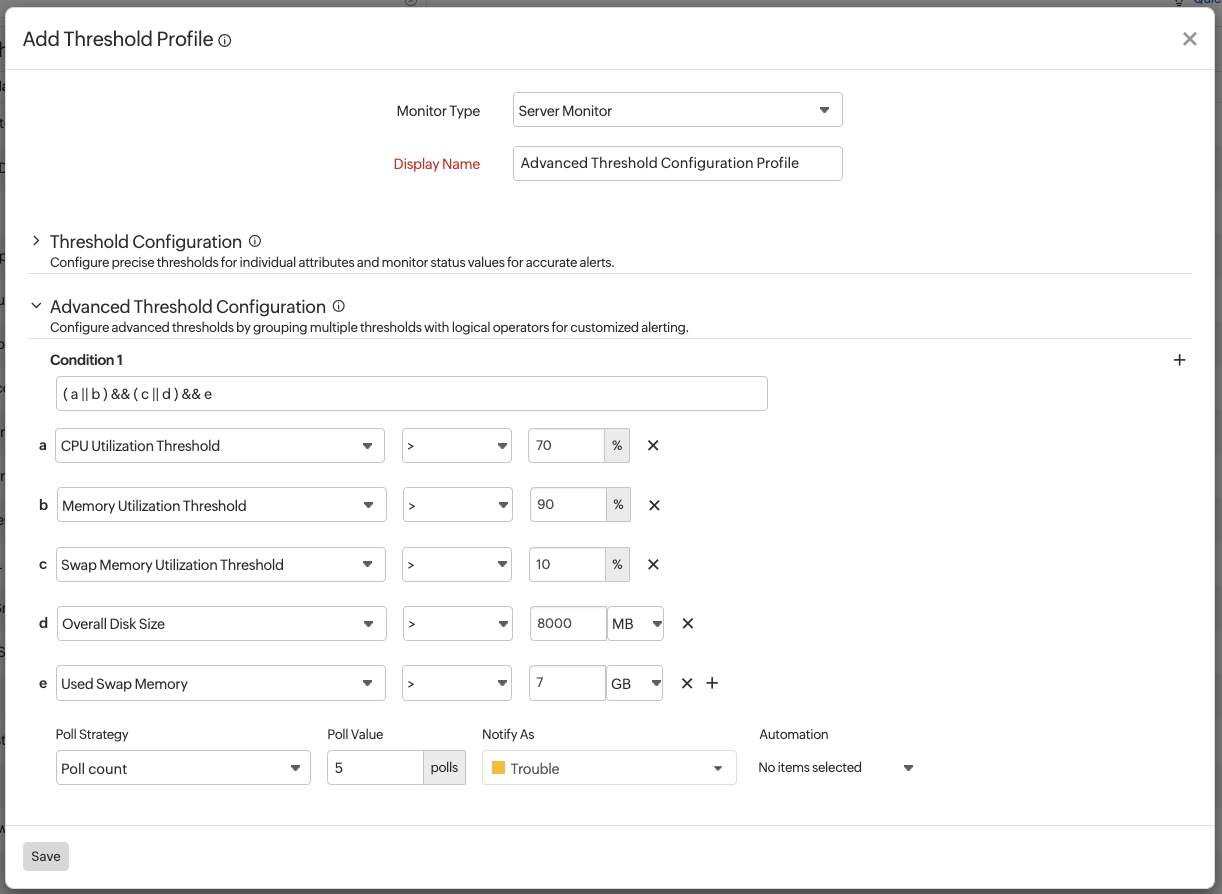
-
- 点击保存。
- 为服务创建的阈值和可用性配置文件将与其他已创建的配置文件一起自动列在阈值和可用性屏幕中。
注意具有自定义角色的用户可以使用查看我的资源选项筛选并查看他们创建的资源。
编辑阈值和可用性
- 点击您要编辑的配置文件。
- 在添加阈值和可用性窗口中编辑需要更改的参数。
- 点击 保存。
删除阈值和可用性
- 在阈值和可用性屏幕中点击需要删除的配置文件。
- 将跳转到添加阈值和可用性窗口。
- 点击 删除。
您可以随时通过汉堡菜单图标在阈值配置文件列表中克隆阈值配置文件或删除它。配置宕机规则以减少以下监视器的误报:
综合事务
Web 事务 | REST API 事务 | Web 事务(浏览器) | 综合移动应用
互联网服务监视器
网站 | 网页速度(浏览器) | REST API | SOAP Web 服务 | DNS 服务器 | SSL / TLS 证书 | 邮件投递 | 端口(自定义协议) | POP 服务器 | SMTP 服务器 | Ping | FTP 服务器 | NTP 服务器 | FTP 传输 | ISP 延迟 | 应用集群
虚拟化监控
本地轮询器 | VMware ESX/ESXi 服务器 | VMware 虚拟机 | VMware 数据存储 | VMware 资源池 | VMware 快照 | VMware 集群
VMware VDI: Horizon
VMware NSX-T: VMware NSX-T Manager | VMware NSX-T 网关 | VMware NSX-T 节点
Nutanix: Nutanix 集群 | Nutanix 主机 | Nutanix 虚拟机 | Nutanix 存储容器
XenServer:XenServer 虚拟机 | XenServer 主机
备份监控
Veeam: 备份服务器 | Azure 备份设备
Commvault: Commvault Command Center
Zerto: Zerto Analytics 监视器
AWS 监控
EC2 实例 | RDS 实例 | S3 存储桶 | S3 对象 URL 端点 | DynamoDB 表 | 经典负载均衡器 | 应用负载均衡器 | SNS 主题 | Lambda | ElastiCache | 网络负载均衡器 | SQS | CloudFront | Kinesis 服务 | Elastic Beanstalk | Direct Connect | VPC-VPN 连接 | API Gateway | Route 53 健康检查 | Route 53 解析器 | Route 53 托管区域 | Route 53 托管区域记录集 | 网关负载均衡器 | Systems Manager | Amazon AppStream 2.0
服务器监控
服务器监视器 | 服务器监视器(无代理) |插件 | Exchange | SQL | IIS | SharePoint | Office 365 | SMART 磁盘
网络监控
网络设备 | NetFlow 监视器 | NCM 设备 | VoIP 监视器 | WAN 监视器 | IP 地址管理(IPAM) | 无线局域网控制器(WLC)| Cisco Meraki | Cisco ACI | VMware SD-WAN | Aruba Central | Cisco Catalyst SD-WAN