EC2 实例和 EBS 卷的阈值配置
Site24x7 利用各种 AWS 服务级 API 自动发现每个可用区内所有正在运行的 EC2 实例及其挂载的 EBS 卷,并在 Site24x7 控制台中为每个实例创建对应的 EC2 CloudWatch 监视器。
当 EC2 实例(普通实例或自动扩缩容实例)被发现并添加为监视器时,系统将为其分配默认阈值配置文件。请注意,该配置文件不会预填任何阈值,您可以编辑默认配置文件,也可以自行创建新的配置文件。
请按照以下步骤,为已监控的 EC2 实例及其挂载的弹性块存储(EBS)卷创建新的阈值配置文件。如需了解如何创建告警联系人和自定义告警设置,请访问我们的用户与告警管理页面。
概述
- 为 EC2 CloudWatch 监视器配置阈值
- 为 EBS 卷配置阈值
- 为集成 EC2 实例监视器配置阈值
为 EC2 CloudWatch 监视器创建阈值配置文件
- 单击管理 > 配置文件 > 阈值和可用性。
- 在阈值和可用性页面单击添加阈值 。
- 填写以下信息:
- 监视器类型:从下拉列表中选择 EC2 实例监视器。
- 显示名称:提供用于标识的标签。
下方将显示 EC2 实例和 EBS 卷支持的性能指标。在相应字段中填写值,设置条件(>、<、>=、<=),并为每个属性配置告警策略。您设置的值将定义阈值。当 EC2 实例 CloudWatch 监视器发生阈值违规时,其状态将从"正常"变为"警告",并触发告警。配置完阈值值后,可保存配置文件。保存后,该配置文件将显示在阈值和可用性页面中。
阈值配置文件中包含以下字段:
自动扩缩容实例终止通知
切换为"是",可在自动扩缩容创建实例时收到通知。
自动扩缩容实例创建通知
切换为"是",可在自动扩缩容终止实例时收到通知。
代理故障通知
"代理故障通知"切换框仅在您已在已监控的 EC2 实例上部署 Linux 或 Windows 代理时才会生效。
状态检查失败通知
当特定硬件或软件问题开始影响您的 EC2 实例环境时,立即收到告警。
默认情况下,EC2 状态检查失败(包括系统状态检查和实例状态检查失败,适用于普通实例和自动扩缩容实例)的告警均已启用。通过切换框,您还可以配置状态检查失败时的通知方式,将切换设为"严重"、"警告"或"宕机"。如果您认为状态检查不是必要的,可以进入 EC2 实例附加的阈值配置文件,将切换设为"否"来关闭。竞价实例终止通知
默认情况下,所有新连接 AWS 账户的竞价实例中断(终止)告警通知均处于禁用状态。如果您认为竞价队列终止的告警通知是必要的,可以进入附加的阈值配置文件,将切换设为"是"以启用,或创建一个阈值配置文件并批量分配给已监控的竞价队列。
预留实例终止通知
默认情况下,预留实例终止(标准型、可转换型和计划型)的告警均处于禁用状态。如果您认为有必要接收通知,可进入已监控预留实例的阈值配置文件,将切换设为"是"以启用。您也可以创建新的阈值配置文件并批量分配。
EMR 实例终止通知
默认情况下,为 EMR 集群节点(主节点、核心节点和任务节点)提供支持的 EC2 实例组的终止告警处于静音状态。如果您需要邮件告警通知,可进入已监控实例的阈值配置文件,将切换设为是。
卷状态检查失败通知
选择是,可接收 EBS 数据卷潜在数据不一致的通知。AWS 每 5 分钟自动执行一次卷状态检查。检查通过时,卷状态报告为"正常";检查失败时,卷状态报告为"受损"。
GPU 连接检查失败通知
选择是,可接收 EC2 实例与 GPU 之间潜在连接问题的通知。AWS 每 5 分钟自动执行一次 GPU 连接检查。检查通过时,GPU 连接状态报告为"正常(UP)";检查失败时,状态根据定义的属性报告为"宕机/警告/严重"。
GPU 健康检查失败通知
选择是,可接收 EC2 实例所连 GPU 潜在健康检查失败的通知。AWS 每 5 分钟自动执行一次 GPU 健康检查。检查通过时,GPU 健康状态报告为"正常(UP)";检查失败时,状态根据定义的属性报告为"宕机/警告/严重"。
加速器健康检查失败通知
选择是,可接收 EC2 实例所连弹性推理加速器(EI Accelerator)潜在健康检查失败的通知。AWS 每 5 分钟自动执行一次 EI 加速器健康检查。检查通过时,EI 加速器健康状态报告为"正常(UP)";检查失败时,状态根据定义的属性报告为"宕机/警告/严重"。
加速器连接检查失败通知
选择是,可接收 EC2 实例与弹性推理加速器(EI Accelerator)之间潜在连接问题的通知。AWS 每 5 分钟自动执行一次 EI 加速器连接检查。检查通过时,EI 加速器连接状态报告为"正常(UP)";检查失败时,状态根据定义的属性报告为"宕机/警告/严重"。
EC2 属性
通过 CPU 使用率、磁盘 I/O 和网络流量等性能指标监控您的 Amazon EC2 实例。Site24x7 为所有已发现的 EC2 实例采集标准性能数据,完成后您可以通过 Site24x7 界面为每个支持的属性配置阈值。

卷阈值配置(EBS 属性)
检测弹性块存储卷上的存储和 I/O 问题。为每个挂载的 EBS 卷设置带宽、延迟和吞吐量等性能计数器的阈值。
为多个 EBS 卷附加单个全局阈值配置文件
若要为弹性块存储(EBS)卷配置阈值,请访问 EC2 实例阈值配置文件(其中包含所有 EBS 属性)。您可以编辑分配给 EC2 实例的默认阈值配置文件,或创建新的阈值配置文件并批量分配给所有已监控的 EC2 实例。如果同一 EC2 实例挂载了多个 EBS 卷,则为卷属性配置的阈值将适用于所有卷。
为每个挂载的 EBS 卷配置独立阈值
如果您挂载了多个 EBS 卷以增加存储容量或提高 I/O 带宽,例如主要用作根卷,同时添加了两个独立卷分别处理数据库和存储工作负载,则可能需要为每个 EBS 卷配置独立阈值。在这种情况下,您可以访问相应 EC2 实例监视器的"卷"标签页,为每个卷单独设置阈值配置文件。


集成 EC2 实例监视器的阈值配置文件
当用户在已监控的 EC2 实例(通过 CloudWatch 集成监控)上部署代理(Linux 或 Windows)时,将创建集成 EC2 实例监视器。此类监视器将关联两个阈值配置文件:一个针对基本实例级 CloudWatch 指标,另一个针对系统指标。
若要配置阈值,请按照以下步骤导航至集成 EC2 实例监视器页面的编辑部分:
- 在控制台左侧导航面板中,选择AWS,然后选择已监控的 AWS 账户。
- 在菜单下拉列表中,选择EC2 实例,选择您要配置阈值的集成 EC2 实例监视器。
- 单击汉堡图标
 并选择编辑。
并选择编辑。 - 在编辑页面的配置文件部分,您会发现有两个阈值配置文件字段。
阈值可用性配置文件包含与 CloudWatch 关联的标准 EC2 性能计数器。在此处,您还可以配置是否希望在代理故障事件中收到告警,可根据您的判断将通知配置为"警告"或"宕机"。

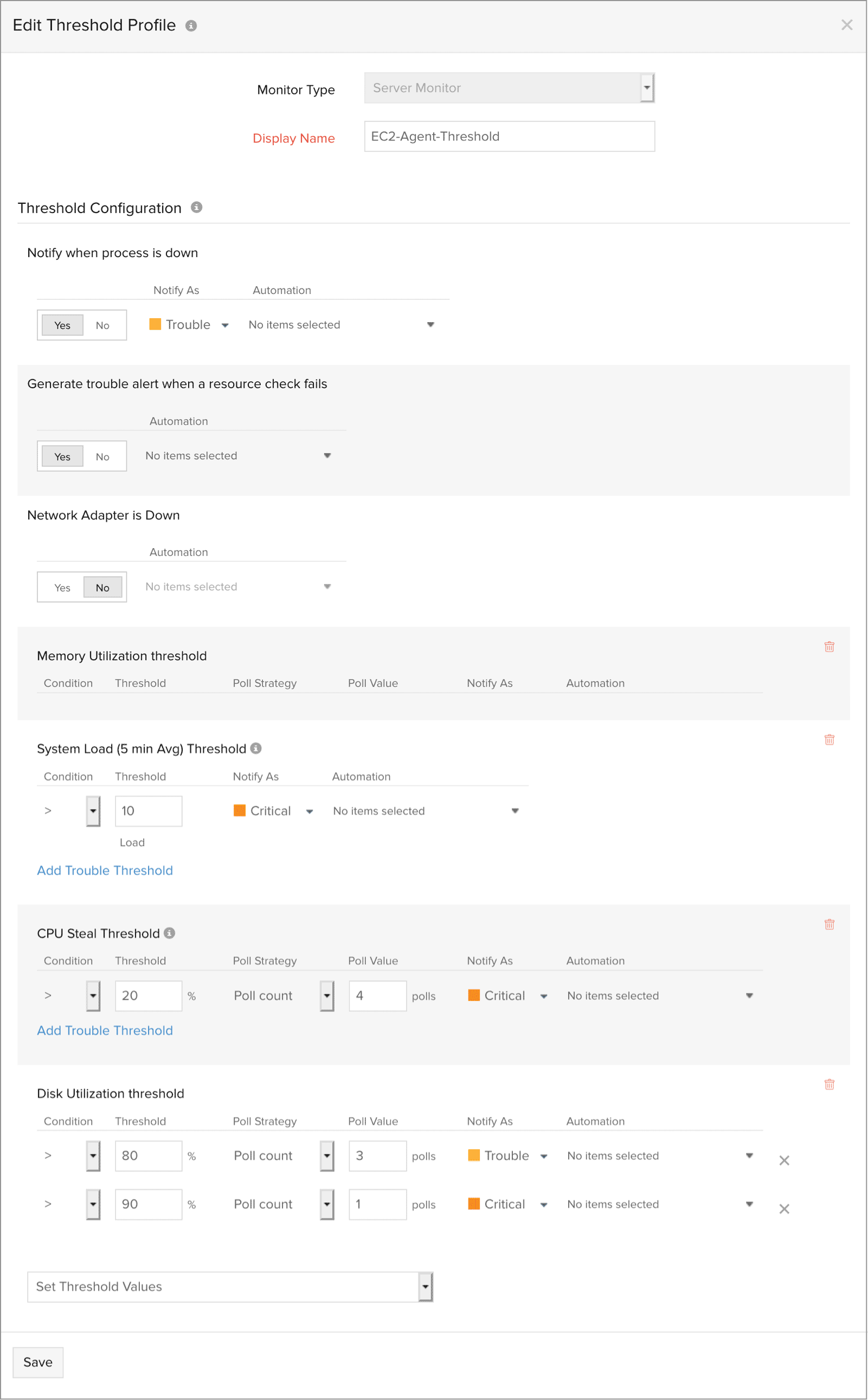
注意您可以选择在自动扩缩容实例终止时接收通知。将"自动扩缩容实例终止通知"选项设为"是",监视器将被暂停,并向您发送告警邮件。
高级阈值设置
您还可以通过配置条件和设置告警策略来验证阈值违规。例如,假设您希望在实例 CPU 使用率超过 95% 时收到告警。但网络流量的峰值可能会触发 CPU 的临时升高,可能超过 95%。对于这种短期影响,您不需要在一开始就收到告警,也许网络负载会回落,从而降低 CPU 使用率。对于这种情况,您可以配置轮询次数或平均持续时间等告警策略,以验证 CPU 峰值是持续性的还是短暂的。
注意高级阈值设置(策略):
轮询次数是验证阈值违规的默认策略。您可以对指定的阈值策略应用多个条件(=、>、<、>=、<=)来验证阈值违规。当应用于以下任意阈值策略的条件成立时,监视器状态将变为"警告":- 在轮询次数(轮询数)期间验证阈值条件:当应用于阈值值的条件在指定的"轮询次数"内持续成立时,监视器状态变为警告。
- 轮询次数(轮询数)内的平均值:当配置的轮询数期间属性值的平均值持续满足阈值条件时,监视器状态变为警告。
- 时间持续期间(分钟)内验证的条件:当在配置的时间持续期内所有轮询持续满足应用于阈值值的条件时,监视器状态变为警告。
- 时间持续期间(分钟)内的平均值:当配置的时间持续期内属性值的平均值持续满足阈值条件时,监视器状态变为警告。
默认情况下不会应用多次轮询检查策略。在无法应用任何策略的情况下,仅对单次轮询验证阈值违规。注意为确保针对"策略 3:时间持续或策略 4:时间持续内平均值"所应用的阈值违规检测条件按预期工作,您必须确保指定的时间持续时长至少是该监视器所应用检查频率的两倍。