使用事件关联进行故障排除
事件关联将来自多个模块(如应用程序、数据库、服务器和网络组件)的相关事件连接起来,形成事故的统一视图。通过关联来自不同来源的症状,帮助定位根因并加快解决速度。
Site24x7 将相关事件关联起来并列出可能的根因,帮助用户验证原因、深入查看详情、分配或自动化修复操作、传达状态更新、追踪重复出现的模式,以及记录发现结果供日后参考。
使用场景
以下使用场景说明了事件关联如何将相关告警归组为"问题",以实现高效的根因分析和简化的事故故障排除。
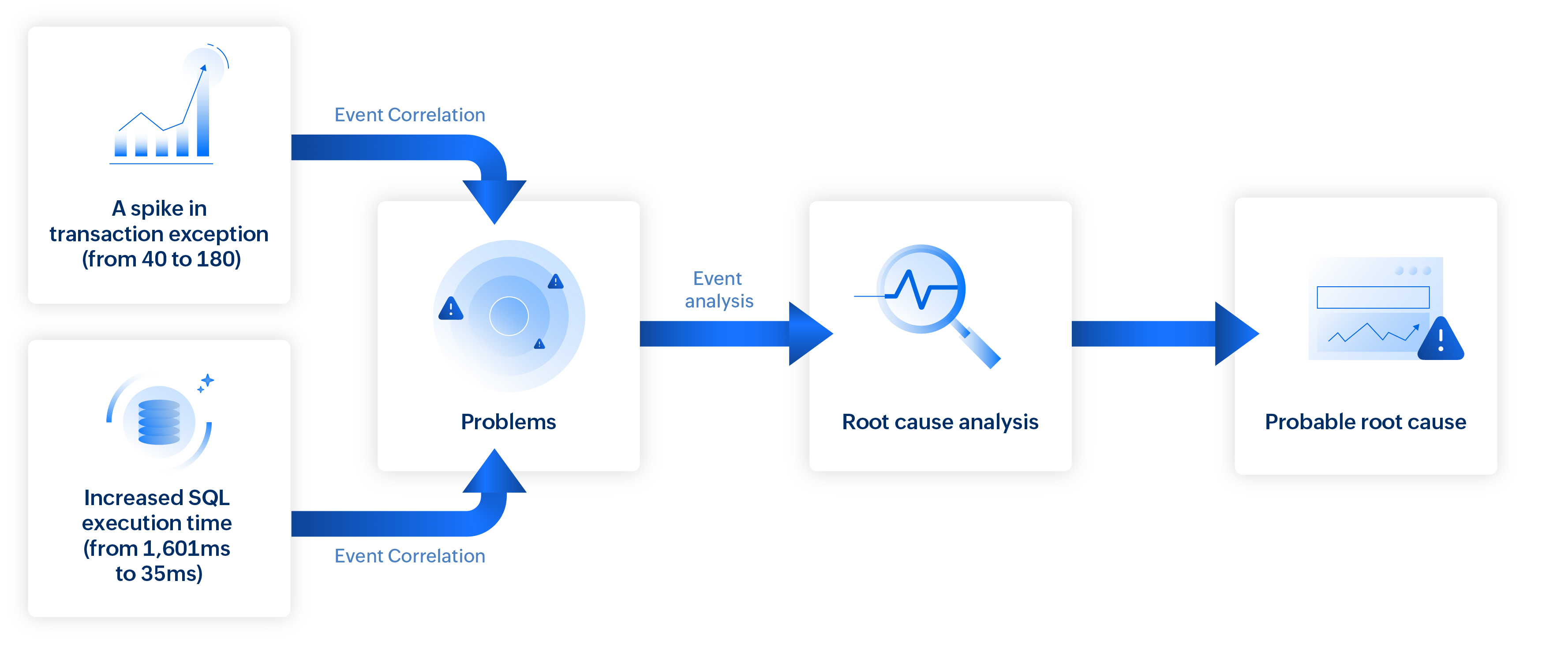
场景 1:定位应用性能监控瓶颈
当应用程序性能下降时,精确定位原因可能颇具挑战。例如,设想应用程序的健康状态突然下降的情况。事件关联配合因果分析,将相关事件串联起来以揭示根因。
在此场景中:
- 事务异常激增(从 40 次增至 180 次)。
- 数据库服务器出现新的 SQL 超时异常。
- SQL 执行时间增加(从 1,601ms 增至 30,105ms)。
- 响应时间增加(从 615ms 增至 2,573ms)。
通过将这些问题连接到单一因果路径,平台支持对失败和成功的事务追踪进行比较,揭示执行流程中的偏差、组件延迟和错误点。
这种有针对性的洞察可帮助您更快解决问题,最大限度减少宕机时间,并确保稳定的服务交付。
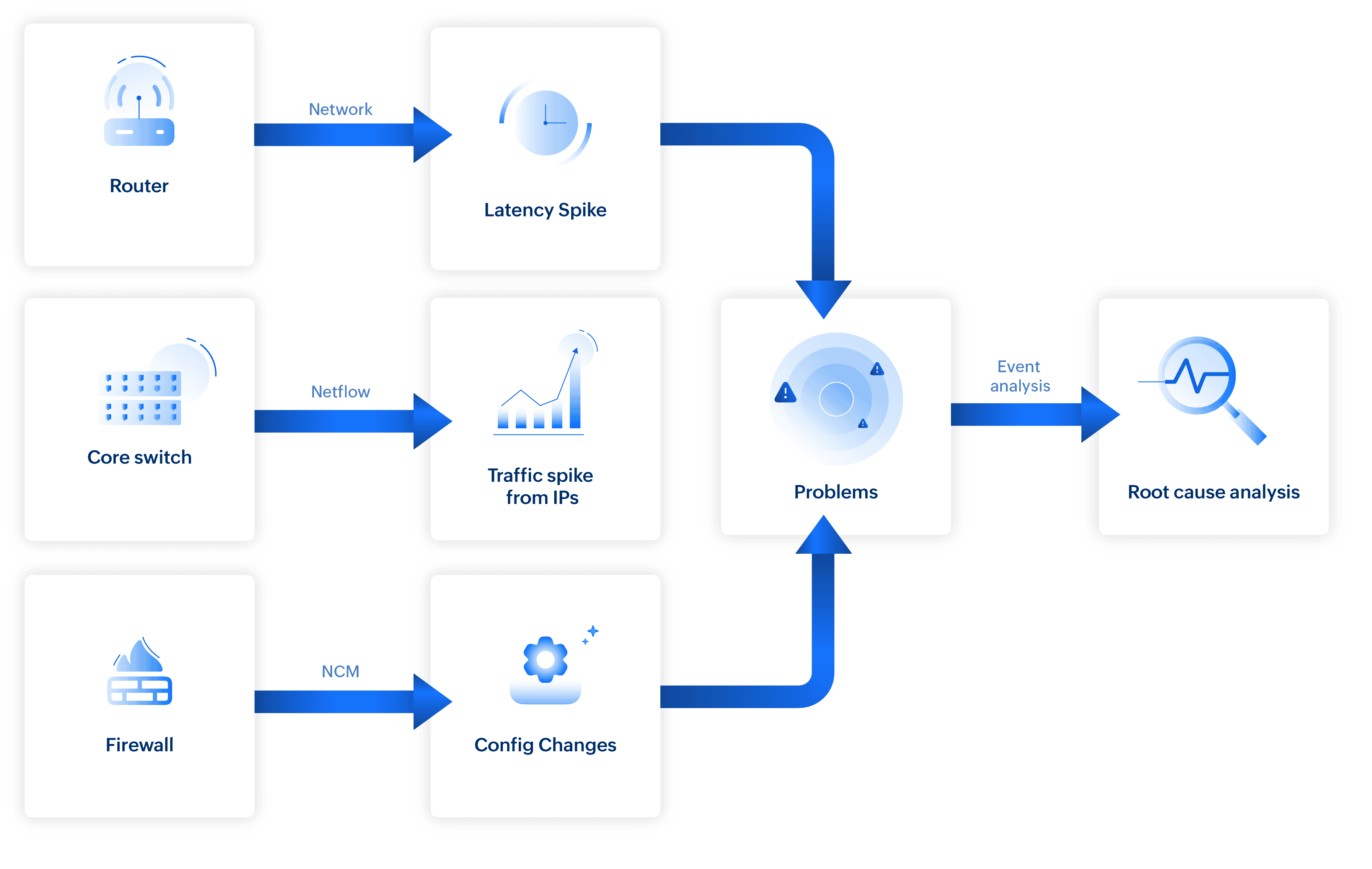
场景 2:隔离网络缓慢的真正根因
在拥有众多交换机、防火墙和路由器等设备的网络中,同时发生的事件很快会令人应接不暇。事件关联通过关联相关事件并过滤噪音来简化这种复杂性,从而揭示真正的原因。
考虑交换机响应时间突然飙升的情况。系统分析来自该交换机路径上(通过二层拓扑图)所有网络设备在同一时间发生的事件:
- 网络流量监控:在被监控的接口上检测到异常带宽峰值(例如,来自特定应用程序或源地址的流量突然增加)。
- NCM:防火墙上发生了最近的配置变更。
- 防火墙:规则被修改(例如,端口过滤器调整)。
- 交换机:独立设备上的 CPU 峰值。
- 属性级指标:响应时间(延迟)峰值。
无关事件(如不相关的 CPU 峰值)被过滤掉。通过将 NetFlow 流量激增与 NCM 防火墙配置变更相关联,创建了一个关联问题,并将其列为交换机响应时间下降的可能根因。
场景 3:识别导致网站应用程序故障的原因
在Web 应用程序中,面向用户的问题(如错误或响应缓慢)可能源于多种底层原因。事件关联帮助将症状与相关的基础设施和服务事件联系起来,以快速定位根因。
当用户在 Web 应用程序中收到 502 Bad Gateway 错误时,可能存在多个底层原因。
在此场景中,Site24x7 分析并发事件:
- 无关服务器上的 CPU 峰值
- ISP 上的临时网络延迟
- 端口 3000 意外终止(严重)
- 相关服务器上的磁盘使用激增(严重)
- 负载均衡器上短暂的内存峰值
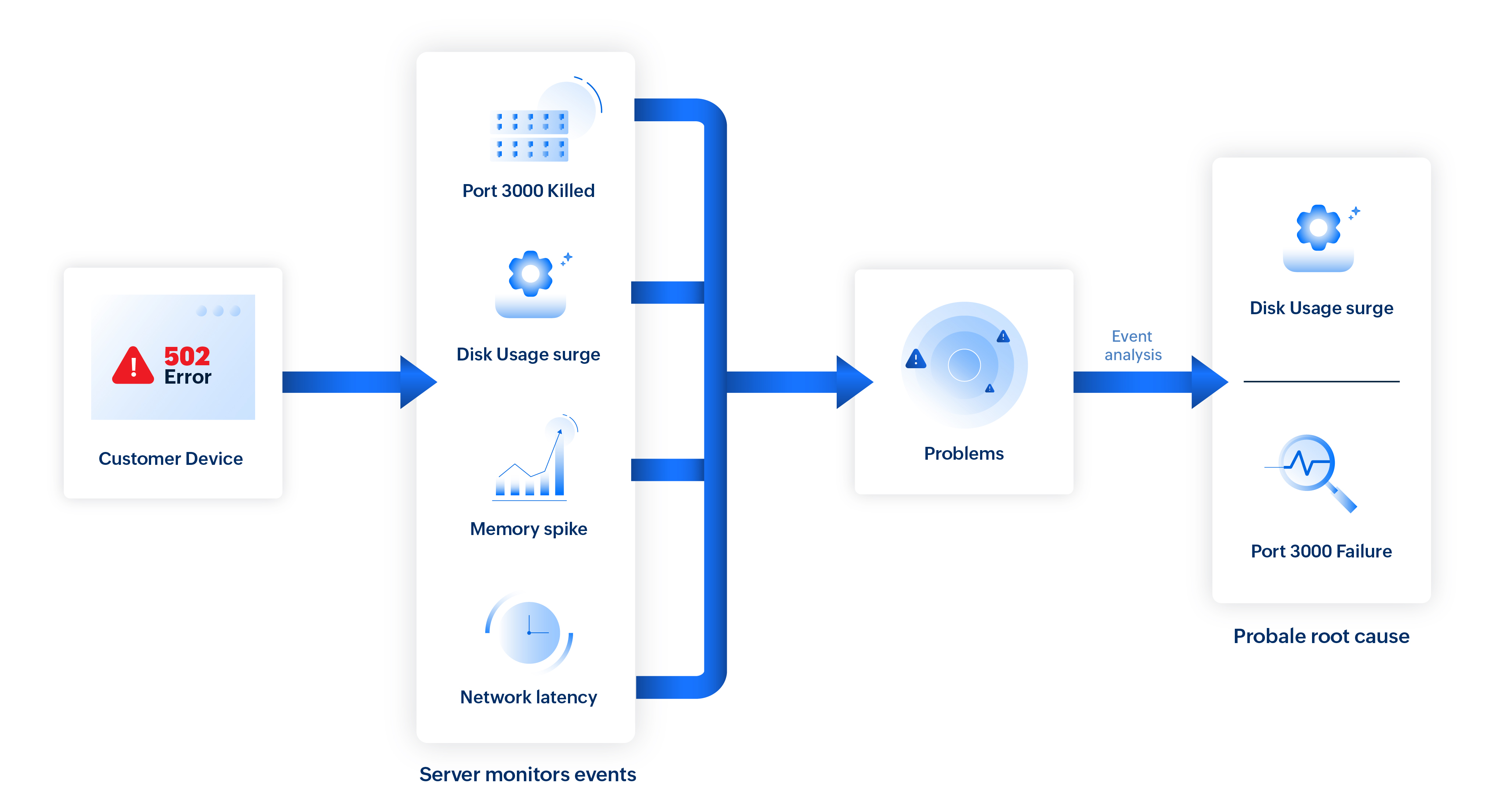
CPU 峰值和内存波动被标记为非影响性事件,而网络延迟在拓扑上并未关联。
因此,剩余事件——端口 3000 终止(直接服务故障)、磁盘使用激增(与基础设施降级相关)以及 502 Bad Gateway(可见症状)——被归为单一问题。
经过进一步的因果分析,端口 3000 故障被识别为主要原因,磁盘使用激增被记为促成因素。
场景 4:追踪 Kubernetes 工作负载中的 5xx 错误
当应用程序在同时运行多个 Pod、节点和部署的 Kubernetes 环境中运行时,突然出现的错误激增可能难以诊断。事件关联通过关联组件间的相关症状来简化这一过程,以识别真正的根因。
例如,在电子商务应用程序中,如果支付网关 API 开始返回间歇性 5xx 错误(如服务器故障或网关超时错误),这表明服务器由于内部错误而无法处理请求。此时,系统分析同一时间段内受影响的节点、Pod 和部署中的事件,以定位来源。
- 节点级信号:检测到节点内存使用量增加,并出现表明节点处于 MemoryPressure 状态的警告。
- Pod 生命周期事件:节点上的多个 Pod 以 "已驱逐:节点资源不足:内存" 为列出原因而终止。
- 容器级指标:多个容器出现 OOMKilled 终止,表明它们超出了内存限制。
- 工作负载行为:随着 Pod 变为不可用,部署的可用副本数量降至低于其期望状态。
- 健康检查与自动扩展:就绪探针在驱逐前失败,而 HPA(水平 Pod 自动扩展器)扩展部署,进一步增加了已承压节点上的内存消耗。
无关事件(如其他命名空间中不相关的节点 CPU 峰值或 Pod 重启)被过滤掉。智能关联将同一节点和命名空间内的所有相关信号分组,揭示了清晰的因果链。
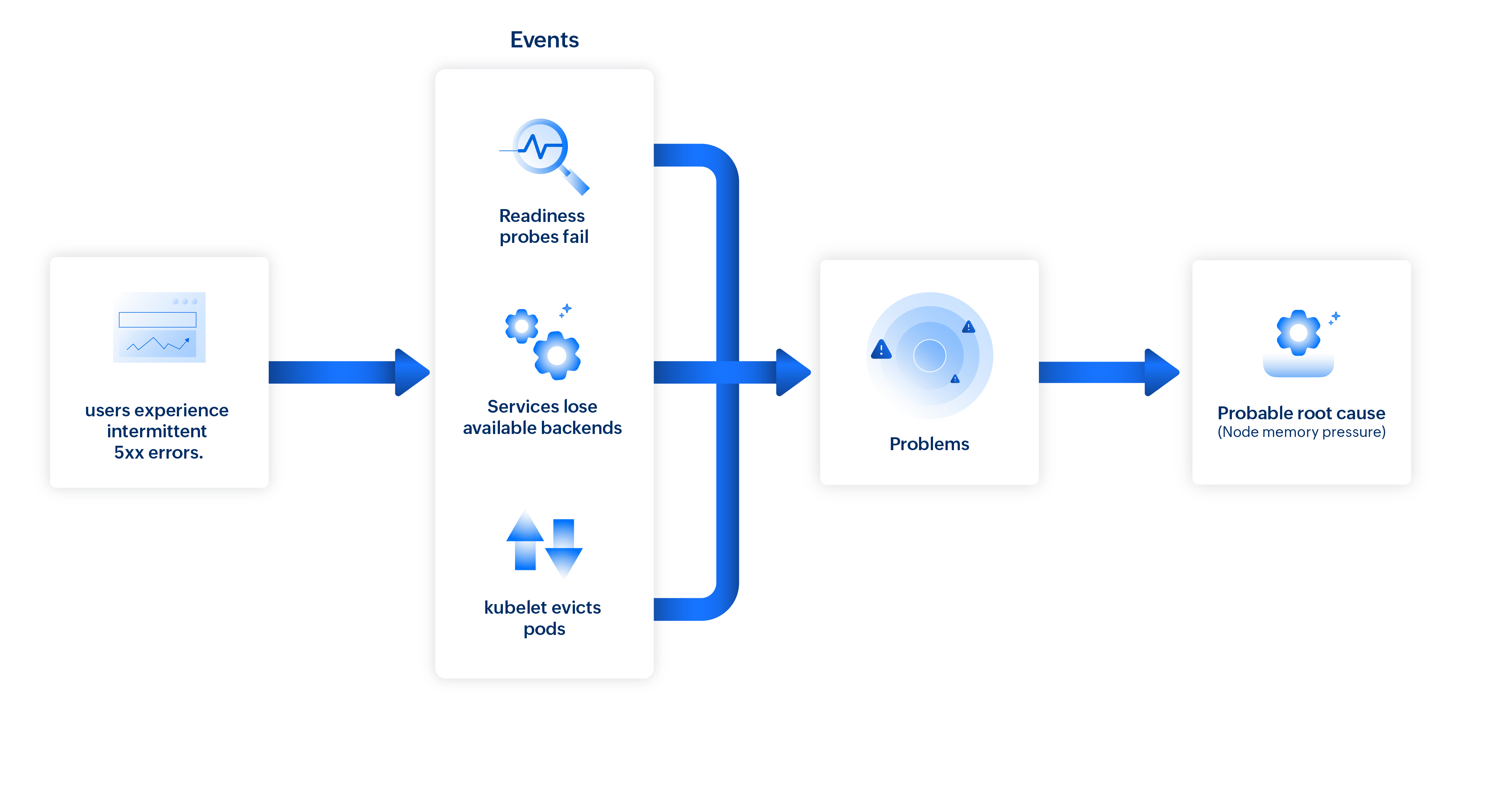
Site24x7 的"问题"功能将这些关联事件汇聚在一起,识别内存压力为 API 故障的可能根因。
相关文章
-
本页内容
- 使用场景