Site24x7 中的事件关联与问题管理
在 Site24x7 中,事件是指受监控资源的状态变化(从正常、宕机、故障或严重变为另一种状态)或性能变化(阈值违规、响应时间峰值、异常等)。乍看之下相互独立的事件,实际上可能通过一个底层变更(例如配置更新或资源故障)相互关联,形成基于因果关系的链条。
Site24x7 识别这种模式,并将相关事件关联到一个统一的"问题"中。除事件关联外,"问题"还会展示一组可能的根本原因事件,帮助评估受影响的组件,并支持优先排序解决方案。
前言
- 事件: 由受监控资源的状态变化(从正常、宕机、故障或严重变为另一种状态)或性能变化(阈值违规、响应时间峰值、异常等)触发的单个告警。
- 问题:源自同一底层问题的多个相关事件被关联形成一个单一的"问题"。
- 根本原因:触发一系列相关事件并导致"问题"形成的主要问题。
- 可能的根本原因:通过关联和分析,基于事件模式、依赖关系以及问题窗口期间的行为识别出的一组可能来源。
- 追踪分析:一种深度分析能力(仅支持 APM),可精确定位导致问题的确切事务、组件或方法。
- 智能组:使用拓扑、依赖关系映射、标签和监视器组自动组织的相互依赖监视器群组,以实现有意义的事件关联。
什么是事件关联?
事件关联是自动识别来自不同监控资源的多个告警之间模式的过程,以发现其底层原因。"问题"基于事件关联对事件进行分组。在事件关联中,智能组融合了机器学习模型、关联方法和 AI 驱动的模式识别,可以:
- 检测相关告警之间的关系。
- 通过将相关事件分组来减少噪音。
- 通过追踪至根本原因来优先处理关键事件。
什么是智能组?
具有相互依赖关系或属于同一环境的监视器会自动组织成智能组。系统利用服务依赖关系映射、应用发现与依赖关系映射 (ADDM)、网络拓扑、应用程序交互以及动态关系(如 Kubernetes),根据事件的相关性和时序检测事件之间的模式。
系统定义的智能组由 Site24x7 自动生成,无法删除。要将其他监视器加入智能组,可以通过标签或监视器组进行关联。
如果监视器具有特定标签或属于与智能组关联的监视器组,则会自动加入该智能组。删除标签或监视器组关联将自动将监视器从智能组中移除。
按以下步骤查看智能组:
- 登录 Site24x7。
- 导航至管理 > 库存 > 智能组。
每个智能组都会显示更多详情,如组内监视器列表、关联的问题、拓扑图、业务视图、告警日志、中断记录等。
事件关联的工作原理
当基础架构或性能问题(例如监视器宕机或响应时间峰值)发生时,Site24x7 从智能组中收集事件和监视器状态。事件根据其相关性和时序进行分组,以确定它们是否是更大底层问题的症状。
通过领域感知关联,系统将特定环境(如应用程序)的知识进行映射,将事件与更深层的上下文相关联。因果分析随后评估事件时间线、依赖关系和行为模式,追溯至最可能的根本原因。这确保关键问题被显示为需要关注的优先问题,同时有效过滤不相关或低影响的事件,显著减少事件数量。
根因分析
通过事件关联创建问题后,系统将执行根因分析,帮助快速准确地识别底层问题。
根因分析基于已知问题模式、系统行为和历史数据的组合来确定最可能的原因。当多个相关事件在同一时间段内发生时,系统会识别共同原因,追踪分析则精确定位事件的确切来源。
了解追踪分析
追踪分析是一种深度分析功能,仅适用于特定应用程序监视器。在根因分析过程中,对于受支持的监视器(如应用性能监视器),可深入到代码级别,精确定位触发问题的确切组件或方法。识别出的事件来源将被列为可能的原因。
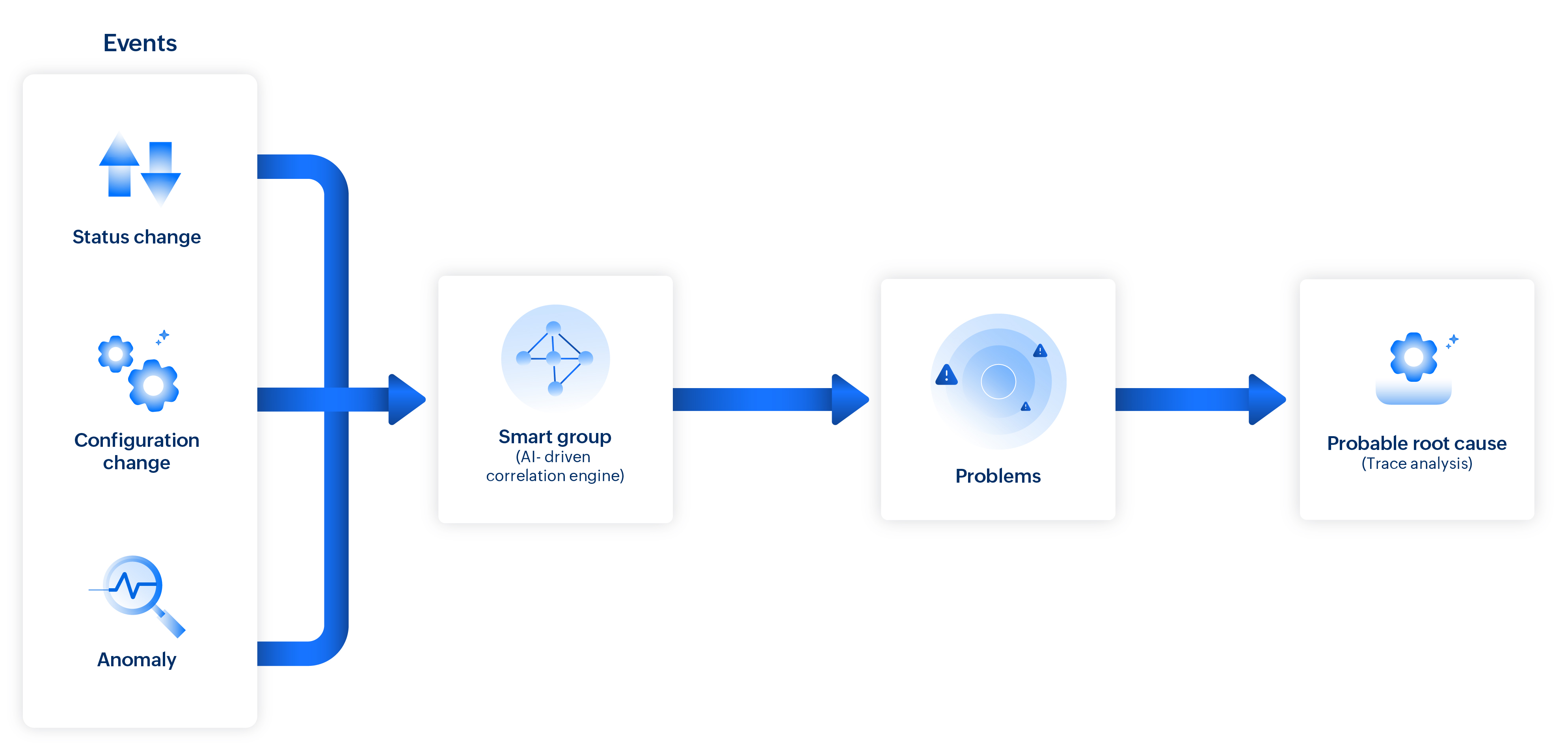
如何关联事件
请按以下步骤查看和分析已关联的问题。
- 导航至告警 > 切换至问题。
- 在左侧面板,您可以:
- 通过选择当前或最近 24 小时选项卡,过滤当前活跃的问题或过去 24 小时内创建的问题。
- 在未确认和已确认选项卡中查看未确认和已确认问题的数量。问题的优先级由系统确定,您可以根据优先级过滤问题。
- 根据关联的智能组和环境过滤问题。
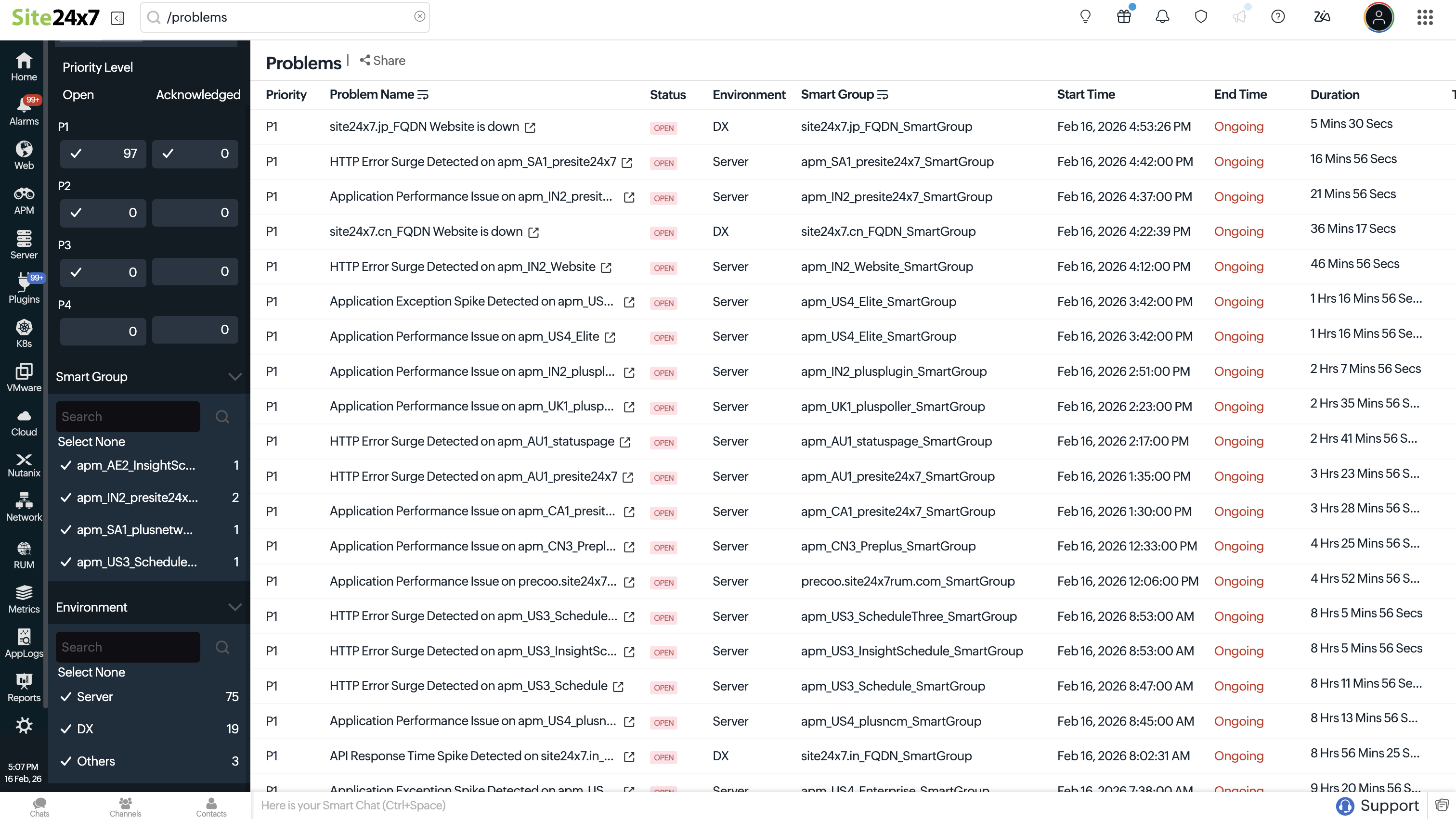
- 问题列表页面显示问题详情:
- 优先级:显示系统评估的问题重要程度。
- 问题标题:显示问题的标题。
- 状态:显示问题是否处于开放或关闭状态。
- 环境:显示检测到问题的顶层类别。
- 智能组:显示与当前问题关联的智能组。
- 开始时间:显示问题的开始时间。
- 结束时间:显示问题的结束时间。
- 持续时长:显示问题持续活跃的时间跨度。
- 技术员:显示负责解决问题的技术员姓名,如果未分配技术员则显示"未分配"。
注意一旦分配了技术员,问题即视为已确认。技术员无法分配给已关闭的问题。
- 点击分享图标
 ,将问题详情下载为 CSV、导出为 PDF 或通过邮件发送。
,将问题详情下载为 CSV、导出为 PDF 或通过邮件发送。 - 要删除问题,点击汉堡菜单图标
 并选择删除。
并选择删除。 - 要进一步分析问题发生的原因、可能的根本原因、受影响的监视器等,点击该问题。
深入分析问题
事件关联完成且根本原因确定后,您可以通过以下选项卡深入了解每个问题的详细信息。
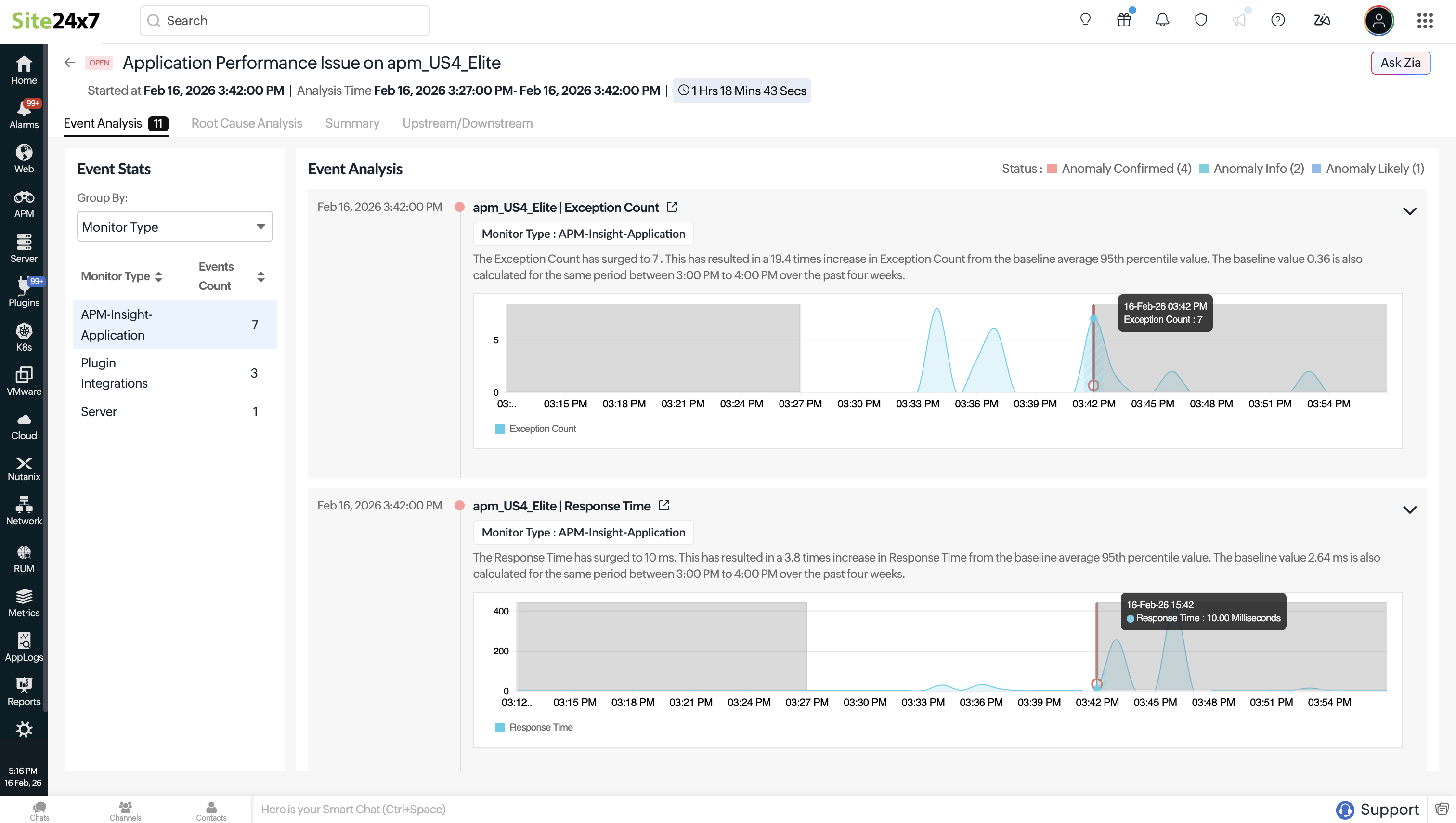
事件分析
事件分析部分显示关联到某个问题的所有事件的时间线。每个事件显示关键详情,如时间戳、受影响资源及属性、监视器类型和严重级别。事件被标记为目标事件,代表主要触发因素,而相关事件则提供支撑上下文。
如果可用,事件将与历史基准进行比较,以显示与正常行为的偏差。您可以使用"分组依据"下拉菜单对事件进行分组,可按以下维度分组:
- 全部
- 监视器类型
- 监视器
- 属性
- 可能的根本原因
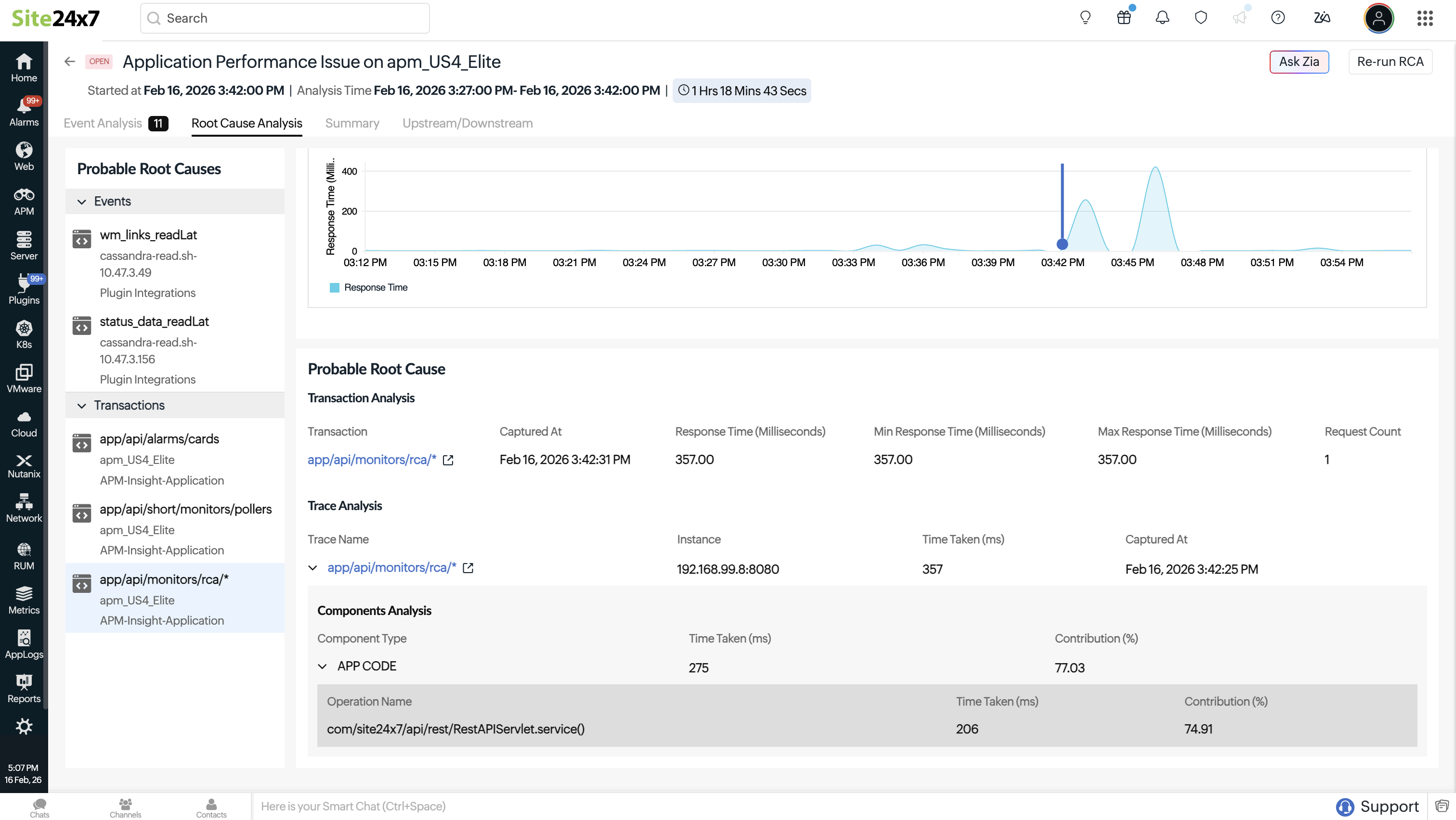
根因分析
根因分析部分通过分析关联事件和性能数据来识别问题最可能的原因,着重分析问题窗口期间受影响组件、事务和指标中的异常行为,以确定问题发生的原因。
本部分通常列出一组可能的根本原因,例如在问题窗口期间与正常行为存在显著偏差的事务或应用程序组件。选择某个可能的原因将显示上下文详情,包括受影响的监视器、监视器类型以及导致问题的具体指标。
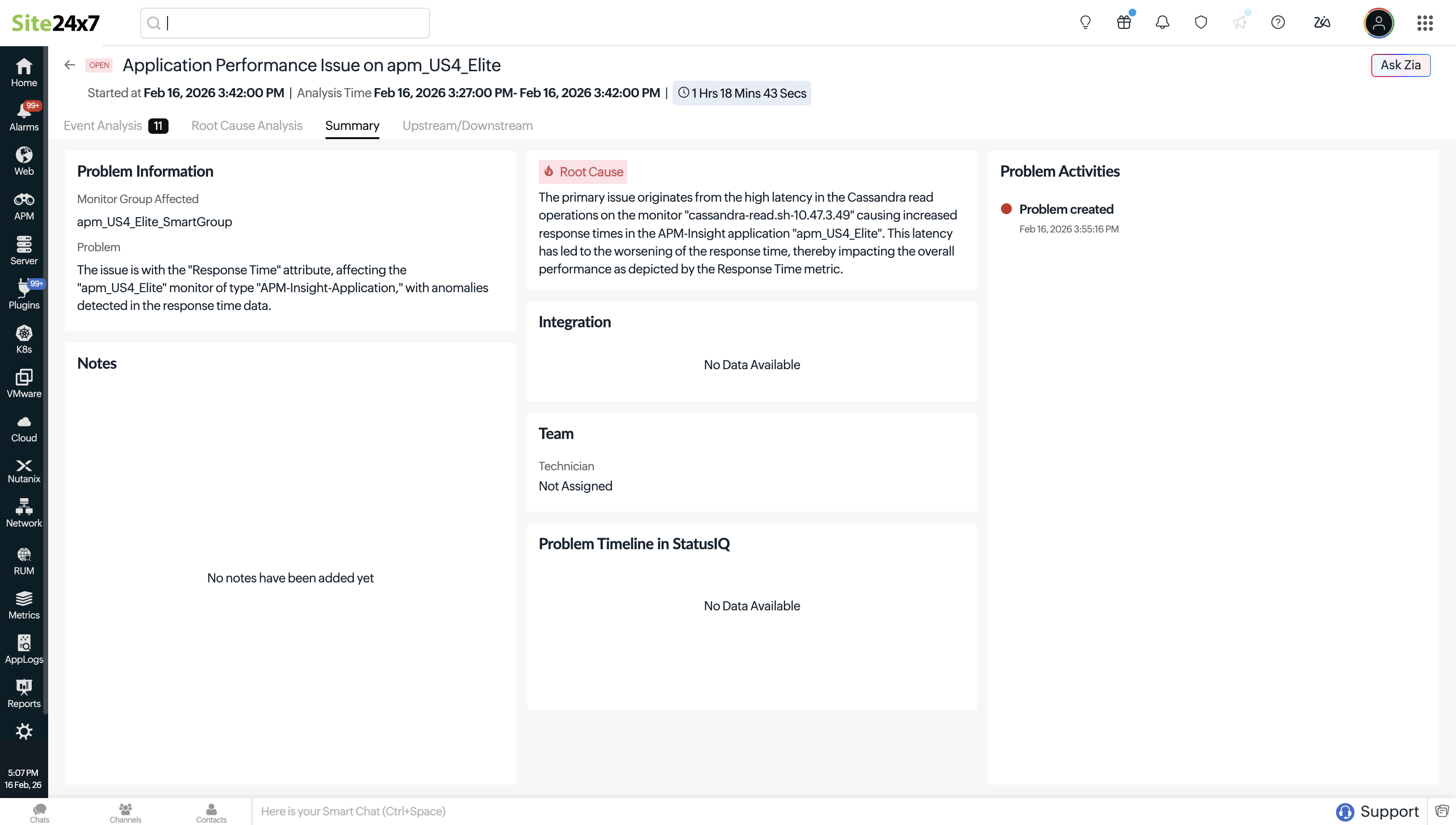
摘要
摘要选项卡提供从检测到解决的问题快速概览,显示问题详情和受影响的监控组。根因摘要解释通过关联和分析识别出的最可能原因。
此外,它还提供关于已分配技术员的详情,并包含集成详情,说明所涉及的外部工具(例如问题共享所通过的工单系统)。
为便于协作和记录,备注部分允许您添加观察结果和修复详情。活动时间线突出显示关键生命周期事件,包括问题创建和解决的时间,让您对问题的进展一目了然。
上游/下游
上游/下游部分显示智能组之间的关系,以及事务、请求或依赖关系在基础架构不同层之间的流向。
- 上游是指向另一个智能组发送请求或依赖关系的源层。例如,将流量路由到应用程序智能组的网络智能组,意味着网络中断可能直接影响应用程序可用性。
- 下游是指接收请求或依赖另一个智能组的目标层。例如,支持 Kubernetes 部署智能组的 Kubernetes 基础架构智能组,意味着基础架构故障可能影响已部署的工作负载。
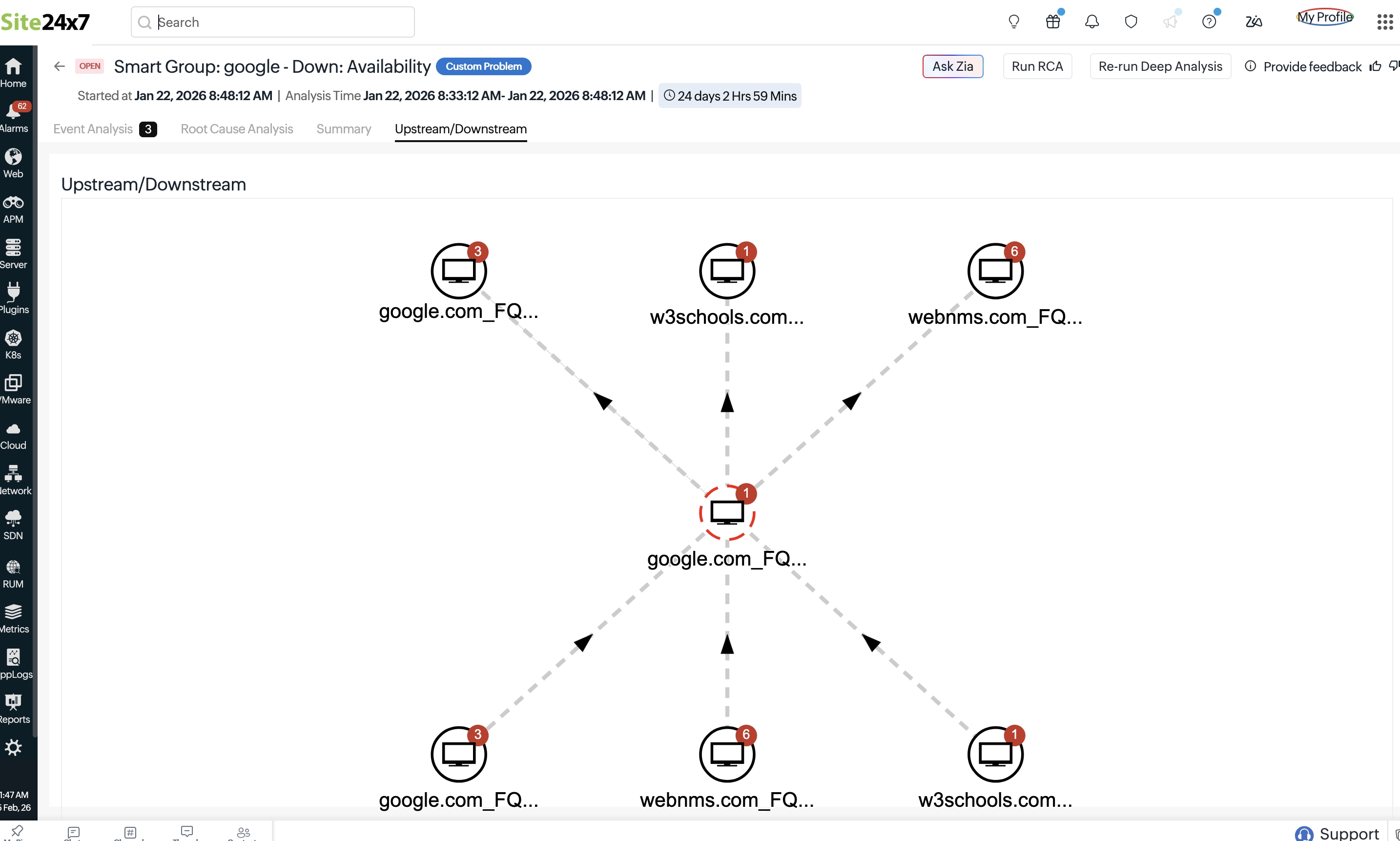
配置后,此设置在"问题"中显示类似拓扑图的结构,帮助可视化服务依赖关系并追踪影响流向。