K8s 监控入门指南:从 0 到 1 搭建稳定观测体系,这 9 个最佳实践别错过

在 Kubernetes(简称 K8s)的使用旅程中,不少人会陷入 “信息过载” 的困境 —— 成百上千的指标、源源不断的日志、层出不穷的工具,很容易让人迷失方向。但实际上,K8s 监控无需从一开始就追求 “面面俱到”,反而应从核心需求切入,逐步搭建适配业务规模的观测基础。本文整理了 9 个新手友好的 K8s 监控最佳实践,帮你避开常见坑,同时介绍 Site24x7 如何简化每一步操作,让监控更高效。
一、集群可用性与健康度:守住 K8s 的 “核心命脉”
集群是 K8s 部署的根基,它的健康状态直接决定了 workload(工作负载)能否稳定运行。监控集群时,需重点关注节点与 Pod 的可用性、命名空间资源使用情况,避免出现资源配额超标、基础设施过度占用的问题,确保 workload 分配均衡。
在 Site24x7 的支持下,你可以实现三大核心功能:
- 实时监控节点、Pod 与 API 服务器:持续追踪节点和 Pod 的健康状态,确保应用获得充足资源;同时监控 API 服务器与 K8s 控制平面的性能,及时发现可能影响整个集群的瓶颈,提前干预以避免停机。
- 可视化命名空间资源使用:清晰展示每个命名空间的 CPU、内存实际使用量,并与预设的资源配额、限制进行对比,快速识别 “资源即将触顶” 或 “过度分配” 的命名空间。
- 即时处理配额违规问题:当命名空间超出资源配额,或 Pod 违反 LimitRange 规则时,Site24x7 会立即发出提醒,避免资源争抢,保障集群内资源分配公平。
- 举个例子:若开发环境的命名空间即将达到内存配额上限,Site24x7 会发送智能告警,明确指出是哪些 Pod 导致资源紧张。此时你可以快速定位到 “资源限制配置错误” 的根源,在问题影响其他 workload 前完成修复。

二、命名空间监控:避免 “资源争抢”,保障多团队公平用资源
命名空间的核心作用是隔离、组织不同团队的 workload。如果不监控命名空间的资源使用,很可能出现 “部分团队过度占用资源,其他团队资源不足” 的情况。通过命名空间级别的监控,能有效落实资源公平分配,优化共享集群的使用效率。
Site24x7 针对命名空间监控提供了三项关键能力:
- 实时监控节点、Pod 与 API 服务器:持续追踪节点和 Pod 的健康状态,确保应用获得充足资源;同时监控 API 服务器与 K8s 控制平面的性能,及时发现可能影响整个集群的瓶颈,提前干预以避免停机。
- 直观展示各命名空间的 CPU、内存使用:通过可视化图表,对比实际使用量与分配的配额、限制,资源使用情况一目了然。
- 及时检测配额违规与 LimitRange 问题:当命名空间的资源使用超出阈值时,立即触发告警,避免 “某个命名空间占用过多资源,影响其他命名空间” 的 “噪音邻居” 效应。
- 保障多环境资源分配公平:确保开发、测试(staging)、生产环境的 workload 都能获得所需资源,不会出现 “测试环境资源溢出,挤占生产环境资源” 的风险。
- 比如:测试环境的命名空间突然出现 CPU 使用超标,Site24x7 会迅速告警,并指明是哪些 Pod 导致资源激增。此时你可以调整这些 Pod 的资源请求与限制,避免问题扩散到生产环境,保障业务稳定。
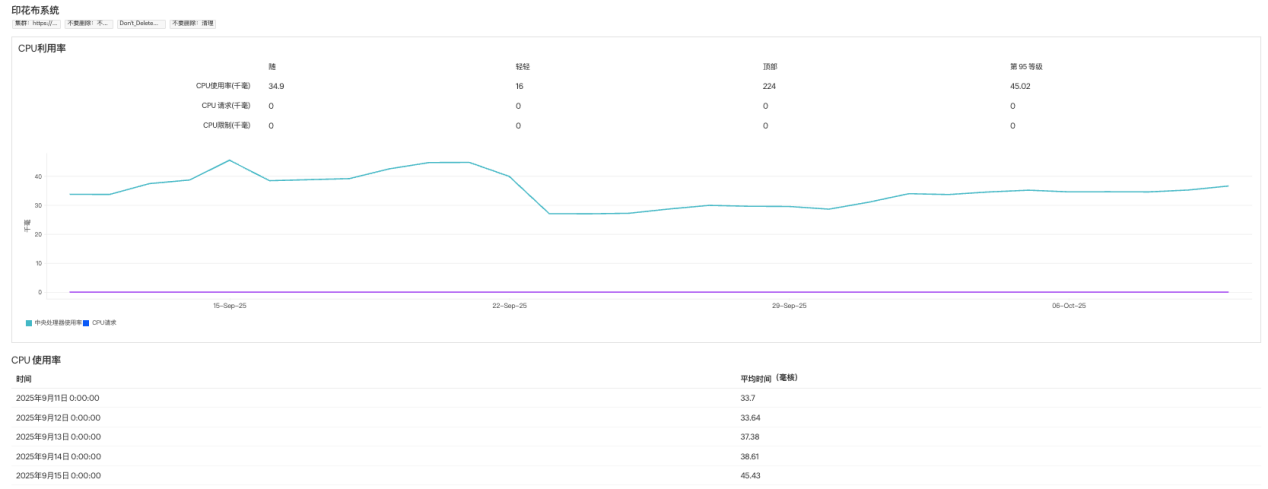
三、节点健康监控:守住 K8s 的 “物理 / 虚拟 backbone”
节点是 K8s 集群的物理机或虚拟机载体,是所有 workload 的运行基础。一旦节点出现健康问题,其上运行的所有 workload 都会面临风险。因此,节点的资源使用、状态监控至关重要。
Site24x7 在节点监控上的能力,可以帮你解决三大痛点:
- 自动发现新节点:无需手动配置,新加入集群的节点会被自动纳入监控范围,避免 “漏监控” 导致的风险。
- 追踪单节点的 CPU、内存、磁盘使用:通过仪表盘实时展示每个节点的资源消耗情况,提前捕捉 “资源紧张” 的信号,比如 CPU 使用率持续偏高、内存不足等。
- 自动管理磁盘空间:当节点磁盘使用率骤升时(如日志文件大量堆积),Site24x7 会自动清理旧日志,防止节点因磁盘满而崩溃,为后续的存储扩容争取时间。
- 举个实际场景:某节点因日志持续生成,磁盘空间快速被占满。Site24x7 检测到后,立即清理过期日志,确保节点上的 workload 正常运行,直到你完成存储扩容,整个过程无需手动干预,避免了业务中断。
四、Pod 监控:盯紧 K8s “最小部署单元”,保障应用响应性
Pod 是 K8s 中最小的可部署单元,应用的运行状态直接依赖 Pod 的生命周期。监控 Pod 的健康状态、资源使用,是确保应用稳定、响应及时的关键。
Site24x7 对 Pod 的监控支持,覆盖了全生命周期管理:
- 自动发现 Pod 动态:Pod 创建或销毁时,会被自动纳入或移出监控,无需人工维护监控范围。
- 可视化 Pod 级别的 CPU、内存使用:精准掌握每个 Pod 的资源消耗,为资源优化提供数据支撑。
- 快速识别 “资源失控” 进程:当某个 Pod 的资源使用远超预期(如 CPU 突然飙升、内存持续占用过高)时,会立即标记该 Pod,方便快速定位问题。
- 比如:某个 Pod 的 CPU 使用率持续飙升,Site24x7 会在仪表盘上突出显示该 Pod。你可以及时介入排查 —— 可能是应用代码存在死循环,也可能是配置错误导致资源消耗异常,在 Pod 过载影响节点前解决问题。

五、设置并监控 CPU、内存限制:杜绝 “噪音邻居”,保障多租户公平
在多租户(多团队共用集群)场景中,“资源争抢” 是常见问题:某个 Pod 无限制占用资源,会导致其他 Pod 资源不足,甚至影响整个集群性能。因此,为 Pod 设置 CPU、内存限制,并监控其使用情况,是保障资源公平、集群稳定的核心手段。
Site24x7 在资源限制监控上,能提供全链路支持:
- 对比 Pod 资源使用与预设限制:实时追踪每个 Pod 的 CPU、内存消耗,并与你设置的 “资源请求(request)”“资源限制(limit)” 进行对比,精准识别 “持续超请求使用” 或 “即将触达限制” 的 Pod,提前发现性能瓶颈或配置问题。
- 超阈值时自动告警:当 Pod 的资源使用超出预设阈值,或因资源不足被频繁 “限流” 时,立即发送告警,避免资源短缺影响应用性能。
- 预防资源争抢:通过清晰的资源使用可视化与及时告警,你可以主动调整资源分配,避免 Pod 间的资源冲突,保障整个集群的稳定运行。
- 例如:某个未设置内存限制的 Pod 开始 “疯狂占用” 内存,导致其他服务响应变慢。Site24x7 检测到该 Pod 的异常资源使用后,立即告警。你只需为其设置内存上限,就能快速恢复集群资源平衡,避免问题扩大。
六、存储与网络监控:别让 “隐性瓶颈” 拖垮应用
很多时候,应用故障不仅源于计算资源不足,还可能是存储或网络出现瓶颈。比如数据库 Pod 因存储 I/O 延迟过高变慢,或 Pod 间通信因网络问题中断。因此,监控存储与网络层,是维持应用稳定性能的关键。
Site24x7 的存储与网络监控能力,覆盖了四大核心场景:
- 追踪持久卷(PV)使用:监控每个 Pod、命名空间的 PV 占用情况,避免 “存储过度分配” 或 “存储空间耗尽” 的问题。
- 识别磁盘 I/O 瓶颈:测量 IOPS(每秒输入输出操作)与延迟,确保数据库、有状态应用等对 I/O 敏感的服务保持响应性。
- 监控 Pod 与服务间通信:检测数据包丢失、DNS 解析失败、kube-proxy 异常等问题,避免网络中断影响服务连通性。
- 可视化网络吞吐量:展示节点、Pod、命名空间的 inbound(入站)、outbound(出站)流量趋势,快速定位流量异常。
- 比如:数据库 Pod 突然响应变慢,通过 Site24x7 可以看到,是持久卷(PV)饱和导致磁盘 I/O 延迟骤升。此时你只需扩容 PV 存储,就能在问题影响业务前完成修复,保障数据库正常运行。

七、尽早开启日志与分布式追踪:从 “知其然” 到 “知其所以然”
metrics(指标)能告诉你 “发生了什么”,比如 “CPU 使用率超标”“Pod 异常重启”;但要知道 “为什么会发生”,还需要日志与分布式追踪。没有日志和追踪,排查故障就像 “盲人摸象”,效率极低。因此,尽早搭建日志与追踪体系,是 K8s 监控的重要一步。
Site24x7 在日志与追踪上的支持,能帮你大幅提升调试效率:
- 集中管理全维度日志:将容器、节点、集群的日志聚合到一个可搜索的仓库中,减少 80% 的手动日志收集工作,无需在多个组件间切换查找日志。
- 关联追踪与指标:将分布式追踪数据与相关指标结合,形成 “指标看现象,追踪找根源” 的闭环,提供更全面的应用性能视角。
- 快速排查故障:通过集中化的日志、追踪、指标分析平台,快速定位性能瓶颈(如某个 API 调用耗时过长)、功能错误(如接口返回异常),缩短故障修复时间,提升应用可靠性。
- 举个例子:某服务响应变慢,通过 Site24x7 关联指标与追踪数据,发现是 “服务调用后端数据库的某个 API” 耗时过高。你只需优化该数据库查询语句,就能快速恢复服务性能,避免问题持续影响用户。
八、使用就绪探针与存活探针:避免用户访问 “故障服务”
就绪探针(readiness probe)与存活探针(liveness probe)是 K8s 保障容器健康的核心机制:就绪探针判断容器是否 “准备好接收流量”,存活探针判断容器是否 “正常运行”。如果不配置或不监控探针,很可能出现 “容器已故障,但仍在接收用户请求” 的情况,导致用户体验变差。
Site24x7 对探针的监控支持,能帮你及时发现容器健康问题:
- 持续检查探针状态:实时监控所有容器的就绪、存活探针状态,确保第一时间知晓 “容器未就绪” 或 “容器故障” 的情况。
- 探针失败时自动告警:当容器未通过就绪或存活探针检查时,立即发送告警,让你及时介入处理。
- 缩短故障恢复时间:通过及时告警,你可以快速修复容器问题,或依赖 K8s 自动重启故障容器,减少服务 downtime(停机时间)。
- 比如:某个容器的存活探针检测失败,Site24x7 立即告警。K8s 会自动重启该容器,服务在短时间内恢复正常,用户几乎感受不到中断。
九、建立 “正常行为基线”:让异常无所遁形
如果没有 “正常性能标准”,你很难判断 “当前指标是否异常”—— 比如 “API 响应时间 1 秒”,到底是正常还是偏慢?建立性能基线后,就能快速识别细微的性能退化或异常,提前预防故障。
Site24x7 借助机器学习能力,帮你实现基线化监控:
- 自动生成关键指标基线:通过机器学习分析历史数据,自动定义 K8s 环境的 “正常行为”,无需手动设置阈值,减少人为误差。
- 检测异常与性能漂移:一旦指标偏离基线(如 API 响应时间突然变长、Pod 重启频率升高),立即识别为异常,捕捉潜在问题。
- 异常时触发告警:当资源使用、性能指标出现明显偏离时,自动发送告警,让你在问题影响业务前完成排查与优化。
- 例如:某 API 的平均响应时间从 “500ms” 逐渐上升到 “1.2s”,Site24x7 检测到这一偏离基线的变化后,立即告警。你通过排查发现是 “后端服务连接池配置不足”,优化后恢复了正常响应速度,避免问题进一步恶化。
最后:K8s 监控,先 “夯实基础” 再 “逐步扩展”
K8s 监控的核心不是 “用多少工具”,而是 “盯准关键需求”。想要保障集群稳定,不妨从最基础的 “集群健康、资源使用、日志追踪” 入手,搭建好观测体系后,再根据业务规模逐步扩展监控维度。
一个好的监控平台,能帮你简化 K8s 管理的复杂性 —— 比如 Site24x7 提供的全链路监控、智能告警、可视化仪表盘,让你无需在多个工具间切换,就能获得端到端的观测能力。
毕竟,观测能力不是 “可选项”,而是保障业务 uptime、性能稳定、运维安心的 “必需品”。
如果想进一步了解 K8s 观测的实操细节,不妨从上述 9 个最佳实践开始,一步步搭建属于你的稳定监控体系。





